


![]() Hello! I’m Prabhu Subramanian. I am a passionate Data Analyst and Engineer. I
analyze data meticulously to bring out its various
potentials in building a predictive model, producing an efficient way to explain data through EDA
and visualizations.
I’m an expert in Python (PEP8), SQL, and Tableau.
Hello! I’m Prabhu Subramanian. I am a passionate Data Analyst and Engineer. I
analyze data meticulously to bring out its various
potentials in building a predictive model, producing an efficient way to explain data through EDA
and visualizations.
I’m an expert in Python (PEP8), SQL, and Tableau.
I offer excellent analytical and communication skills. My strive is to learn, teach and enhance my skills as an avid Data Analyst, Cloud Practitioner, and Machine Learning enthusiast with a parallel knowledge of Data Engineering.
Database: MySQL, Microsoft SQL Server, PostgreSQL, Oracle, Snowflake, Arora, Redshift, DynamoDB, Teradata
Cloud Engineering: Google Cloud Platform, Amazon Web Services, Microsoft Azure, Databricks
Business Integration: Tableau, Microsoft Power BI, Excel, SAP, BI HANA
Data Visualization: matplotlib, seaborn, ggplot2, Plotly
Version Control: Git, GitHub, Bitbucket, SVN Tortoise
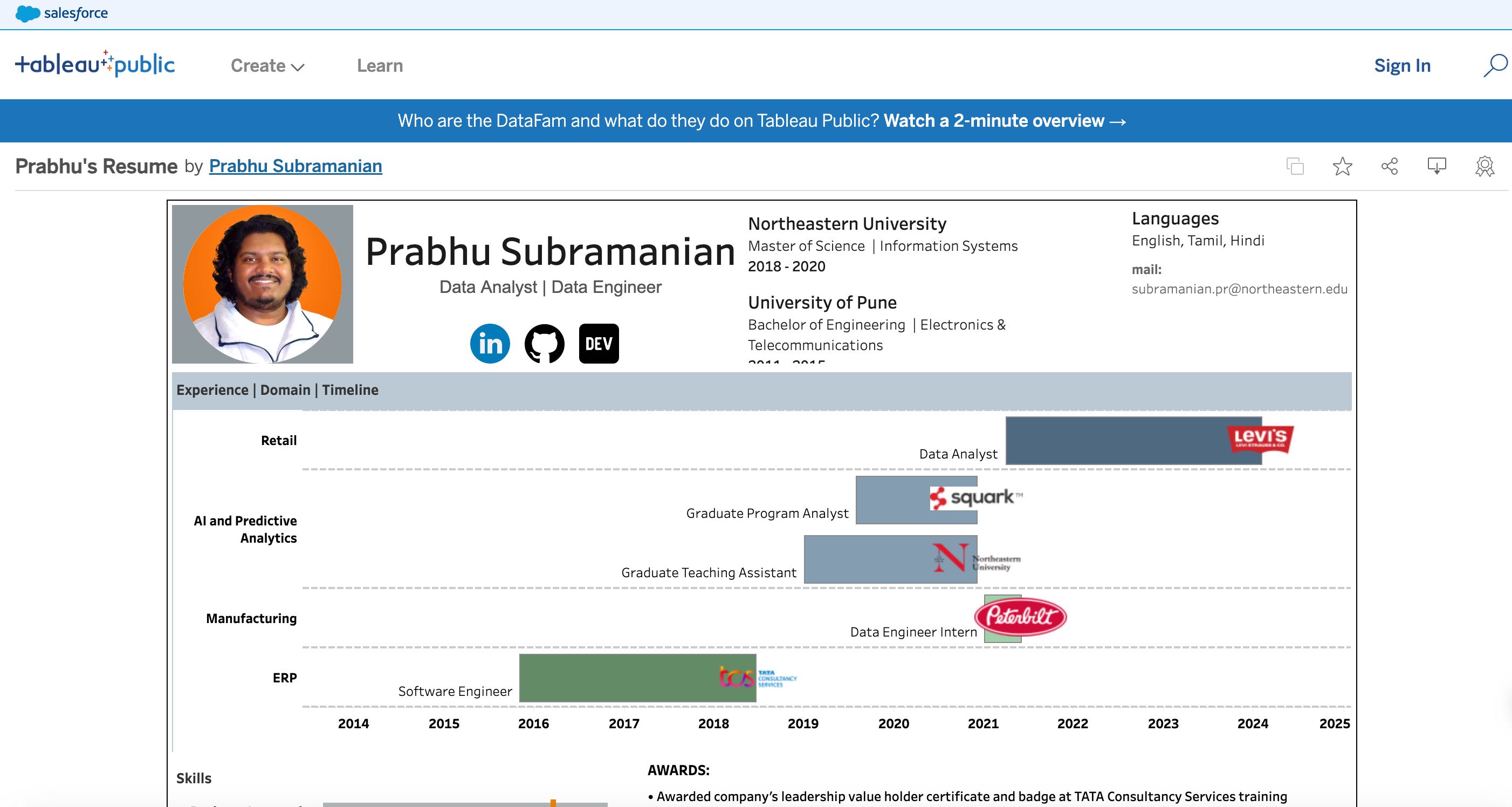
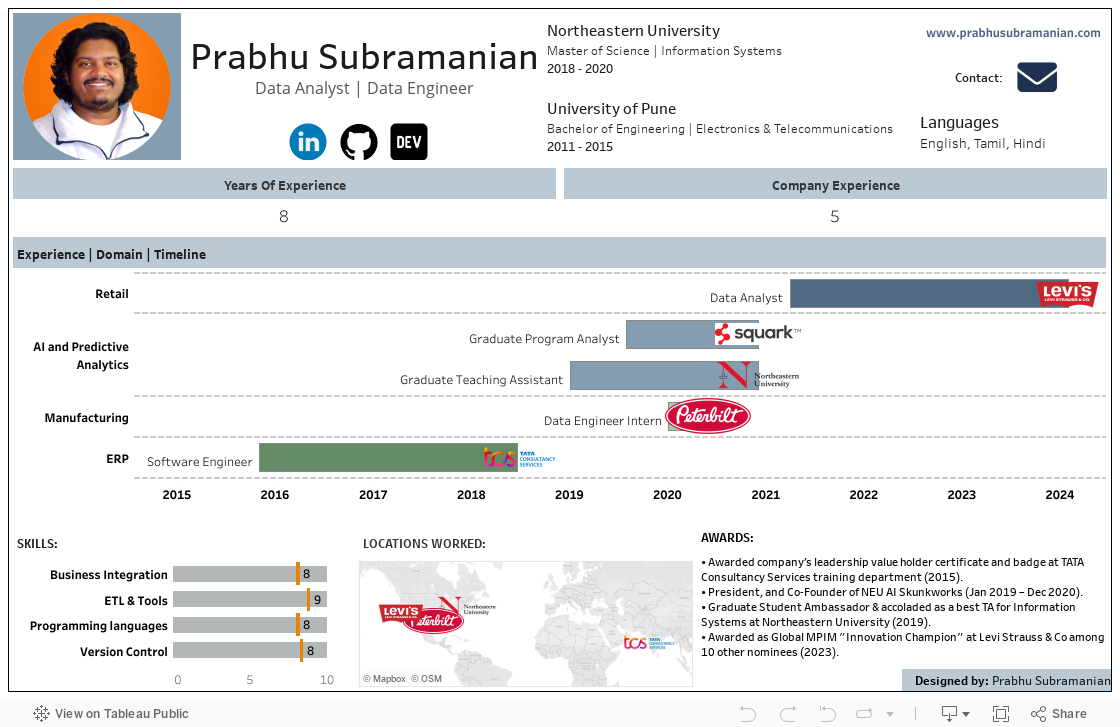
May 2025 - Present
-
COMING SOON...
April 2021 - May 2025
- Designed and implemented interactive dashboards that provide real-time insights into key logistics metrics such as inventory levels, shipping performance, demand forecasts, and delivery timelines.
- Integrated multiple data sources, including warehouse management systems (WMS), enterprise resource planning (ERP) software, and transportation data, to create a centralized analytics platform
- Empowered analysts and business users to extract meaningful insights, reducing dependency on technical teams and improving overall data literacy within the organization.
- Implemented data-driven process improvements, resulting in reduced lead times, enhanced forecasting accuracy, and streamlined logistics workflows.
- Improved data accessibility and usability by enhancing data pipelines, standardizing reporting metrics, and optimizing data visualization techniques.
- Provided guidance as a Subject Matter Expert (SME) for critical reports, and aligning with business objectives for over 500 users.
- Automated and enhanced various reports, ensuring 100% end-to-end automation without any manual intervention. Incorporated intricate logic to dynamically generate reports for daily/weekly/monthly/yearly reporting requirements.
- Innovatively designed and executed multiple Proof of Concepts (POCs) using Python, Alteryx, and ETL techniques, enhancing operational efficiency.
- Utilized PySpark on Databricks to automate reporting solutions and visualize data on PowerBI for business users.
- Developed an API to bridge the gap between Alteryx and SharePoint, enabling comprehensive reporting analysis and saving approximately 15 hours of manual data transfer per week.
- Mentored peers and facilitated training sessions to enhance reporting capabilities and streamline data integration processes.
January 2019 - December 2020
- Enhanced model accuracy by an impressive 70% through the application of advanced NLP techniques such as word2vec & BERT, resulting in more precise predictions and decision-making processes.
- Developed production code integrating the MinIO framework with AWS S3, significantly streamlining data storage and retrieval processes, leading to a 50% reduction in data access time.
- Formalized subprocesses to execute the JVM H2O engine, effectively optimizing computational performance and resource utilization, resulting in a 40% increase in processing speed.
- Developed and devised a multiprocessing and multithreading solution to enhance efficiency further.
- Implemented an automation script using Python and CLI, dramatically reducing developers' testing time by an outstanding 90%, thereby accelerating the development cycle and time-to-market.
- Established testing logs and a web interface through Grafana dashboard integration, enhancing visibility and monitoring capabilities.
- Thoroughly documented all development pipelines on Confluence, ensuring clear communication and knowledge sharing within the team.
January 2020 - June 2020
- Implemented scripts to preprocess and optimize the speed by an impressive 50% for cleaning customer warranty data using Python & SQL, resulting in a significant reduction in data processing time and operational costs.
- Enhanced NLP model accuracy by introducing spelling dictionaries and incorporating manufacturing plant failure modes word corpus.
- Administered data warehouse pipelines from various sources including Snowflake, Teradata, and Excel, deploying CI/CD pipelines using Jenkins and CloudFormation.
- Established a logging and notification pipeline for internal team communication using AWS services.
- Deployed pipeline using Docker, Kubernetes (EKS), and AWS Services - SNS, SQS, SES, S3, EC2, Lambda.
November 2015 - July 2018
- Designed and implemented Enterprise Resource Planning (ERP) dashboards catering to Supply Chain, Manufacturing, and Finance departments, resulting in a 20% increase in supply chain visibility, a 15% reduction in manufacturing downtime, and a 25% improvement in financial forecasting accuracy.
- Achieved a remarkable 68% improvement in application query optimization, leading to a 30% reduction in report generation time and a 25% increase in overall system performance, resulting in significant cost savings and enhanced productivity.
- Improved Customer Self-Service operations by 30%, leading to a 25% rise in satisfaction ratings and a 20% drop-in ticket resolution time, showcasing leadership in operational excellence and customer focus.
- Customized and deployed a Kanban process utilizing SQL functions and triggers, streamlining workflow management.
2018 - 2020
Northeastern University
Relevant Coursework: Data Management & Database Design, Designing Data Architecture & Business Intelligence, Big Data Architecture & Governance, Project Planning & Management
2011 - 2015
University of Pune
Relevant Coursework: Signal Processing, Communication Systems, Digital Signal Processing, Wireless Communication, Embedded Systems, Internet of Things (IoT), Mobile Communication











Tech Recruiter at Company
Prabhu is a dedicated, innovative team member. I supervised Prabhu directly during his time as Graduate Student Ambassador for College of Engineering and he brought many admirable qualities to the program. He is professional, agile, and a true collaborator on projects.

CTO at AI Company
He is a great hard worker, a leader, and a teacher by heart. He is talented and works independently on achieving his goal, hence was recommended for a Teaching Assistant award. His knowledge, skills, enthusiasm, and interest in data engineering makes him a good fit for any innovative team.

Data Scientist at AI Company
I worked on a project with Prabhu when he was a Data Engineer intern at Paccar. Prabhu is a self-motivated person with great work ethics. He was always open-minded to learning new things and always willing to ask important questions. Prabhu was a team player that was always ready to help anyone. For an intern, he showed a deep understanding of many data engineering subjects. I have no doubt that he will be a valuable member of the right data team.
Address
San Francisco, U.S.A
prabhus165@gmail.com